So sánh xâu tiếng việt
Chào mọi người, trong quá trình xử lý text, đọc và so sánh chuỗi thì mình gặp vấn đề như sau : có 2 string nhìn bằng mắt thường thì giống nhau, nhưng khi encode sang utf-8 thì nó cho ra 2 chuỗi binary khác nhau ,ví dụ trên python 3:
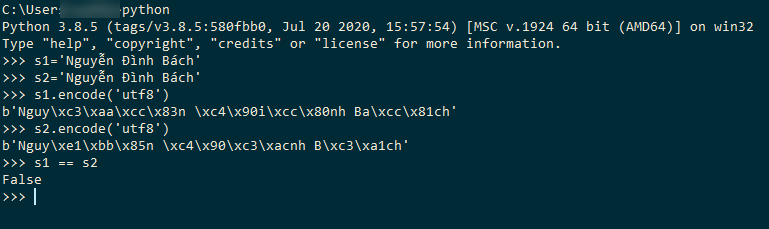
s1 = 'Nguyễn Đình Bách'
s1.encode('utf-8') = b'Nguyxc3xaaxccx83n xc4x90ixccx80nh Baxccx81ch'
s2 = 'Nguyễn Đình Bách'
s2.encode('utf-8') = b'Nguyxe1xbbx85n xc4x90xc3xacnh Bxc3xa1ch'
Nên s1 == s2 sẽ cho ra False. Vậy mình muốn hỏi với những string về mắt thường nhìn giống nhau nhưng encode khác nhau như trên thì có cách nào xử lý để phép so sánh s1_daxuly == s2_daxuly ra kết quả là True không.
Cám ơn mọi người đã đọc bài.






